Kingma & Ba 2017 introduces Adam, an algorithm for gradient optimization that is:
straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data and/or parameters.
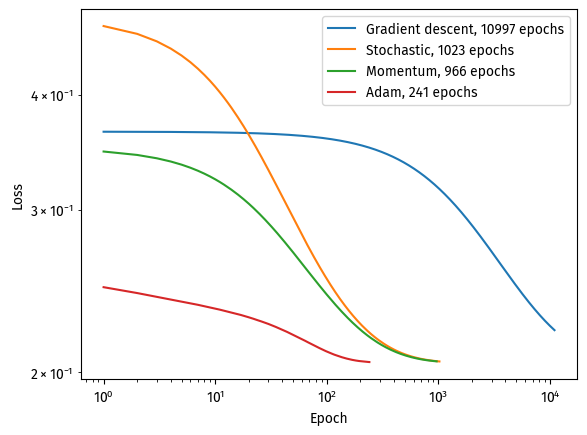
Stocastic gradient descent, with or without momentum, took around 1.82 s.
“Plain” gradient descent took 2.07 s, although 2.07 s is exactly 1 standard deviation away from 1.82 s.
Learning rate
The learning rate determines how much we move along the gradient.
When the learning rate is too large, gradient descent will exceed the optimal minimum; when it is too small, gradient descent will take longer to reach the optimal minimum.
We loop our Adam implementation through multiple learning rates:
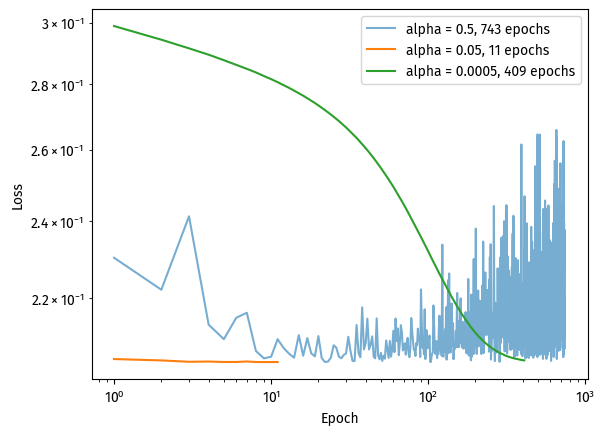
With three different learning rates, we can see a difference in how training loss progressed over time:
Reasonably small, alpha = 0.05: loss decreased quickly, converging in only 11 iterations.
Too small, alpha = 0.0005: loss decreased more smoothly but slowly, converging in 409 iterations.
Too large, alpha = 0.5: loss jumped up and down frequently, converging in 743 iterations.
This shows that indeed, we want a reasonably small learning rate. Small enough to converge, but not too small that converging becomes too slow.
Batch size
We look at another hyperparameter, the batch size.
Because we look at each “batch” separately, the size of these batches, might determine the speed of gradient descent.
Using our reasonable learning rate of alpha = 0.05:
from time import perf_counterbatch_sizes = [2, 10, 20, 50, 100, 200, 500]repeat =5for batch_size in batch_sizes: times = []for _ inrange(repeat): LR = LogisticRegression() start = perf_counter() *1000 LR.fit_adam( X, y, max_epochs=1000, batch_size=batch_size, alpha=0.05 ) end = perf_counter() *1000 times.append(end - start) perf =sum(times) /len(times) num_steps =len(LR.loss_history) plt.plot( np.arange(num_steps) +1, LR.loss_history, label=f"batch size = {batch_size:4}, {perf:> 6.2f}ms, {num_steps} epochs", alpha=0.7 )plt.loglog()legend = plt.legend()xlab = plt.xlabel("Epoch")ylab = plt.ylabel("Loss")
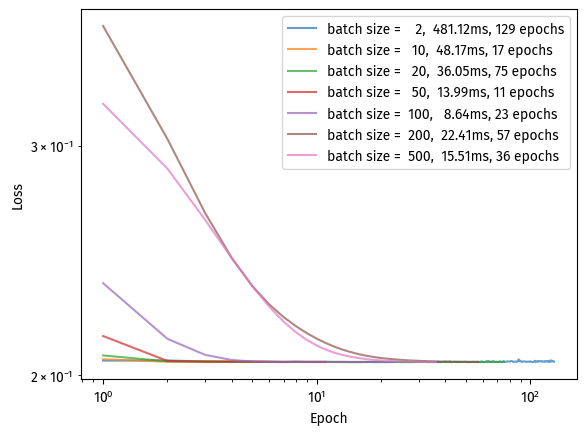
Here, using otherwise identical hyperparameters, we observe that batch size does affect convergence speed and runtime.
A batch size of 2 yielded the most epochs and the longest runtime.
A batch size of 50 converged in the least epochs, although it is slightly slower than a batch size of 100 and 200, perhaps due to more calculations per loop.
Larger batch sizes took more epochs to converge, while maintaining around the same wall clock time.
In conclusion, a reasonable batch size (in this case, 100) strikes a nice balance between wall clock time and the number of epochs needed to converge.
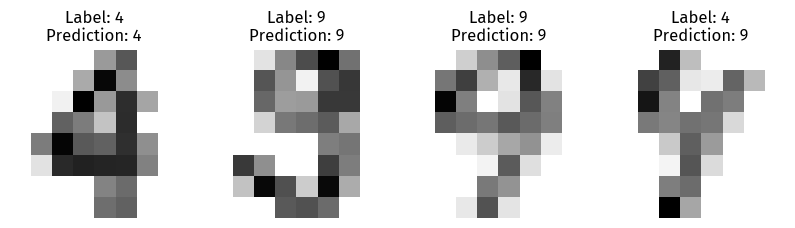
Because we are predicting binary lables, we choose only the numbers 4 and 9. Then, we normalize the X and y labels. Finally, we perform a train-test split.
Momentum: 0.9790
Adam : 0.9860
Confusion matrix for Momentum:
0 1
[[52 2]
[ 1 88]]
Confusion matrix for Adam:
0 1
[[53 1]
[ 1 88]]
We can see that Adam performed slightly better than the momentum method, mis-classifying one less cancerous diagnosis as noncancerous.
This variation, however, might be the result of randomness instead of an actual accuracy difference.
Conclusion
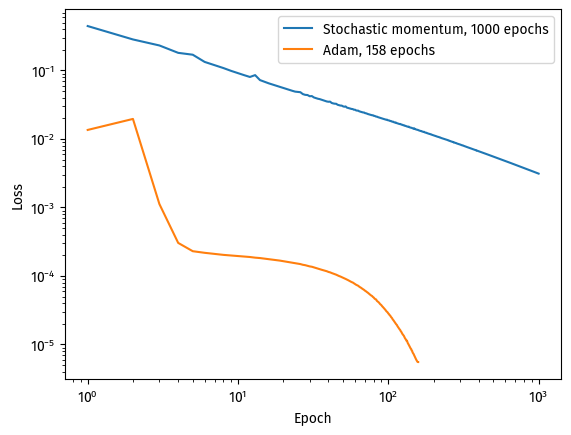
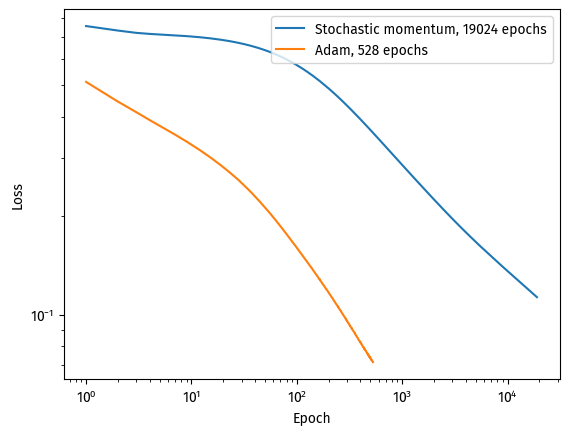
As we have seen, Adam is an efficient optimization on stochastic gradient descent, cutting both the number of epochs and the wall clock time.
Because these are initialized as zeroes, the authors corrects that bias by introducing \hat{m_t} and \hat{v_t}.
Through interacting with a visualization, one can observe that Adam can achieve the global minima faster and more often than SGD, momentum, and RMSProp.
In implementing Adam, we also encountered underflow, which is an important aspect of applying mathematical models to a computer program. It also highlights the importance of using existing frameworks, since these are often well-tested.
Adam itself is built upon AdaGrad and RMSProp. This highlights that work in the field is often built upon others’ work.
Effectiveness
The name “Adam” comes from “adaptive moment estimation”, referring to both the mean m_t (Line 7, “first moment”) and variance v_t (Line 8, “second moment”).
As explained in Section 2, Adam’s effectiveness can be partly explained by two aspects:
The learning rate decays exponentially, as suggested by \alpha_t = \alpha \cdot \sqrt{1-\beta_2^t} / (1-\beta_1^t). This establishes a “trust region” so that \alpha has the right scale.
The ratio of m_t \cdot \sqrt{v_t} is a “signal-to-noise ratio”, determining how much to move the weights vector. If the SNR is small, there is greater uncertainty in the weights, so the algorithm is more cautious.
These are combined in the more efficient algorithm proposed in section 2, which is essentially moving \theta by the product of \alpha_t and m_t \cdot \sqrt{v_t}.